One of my projects over the past couple of years has been Synit, a
Syndicate init (really, systemd and D-Bus) replacement. Synit underpins another
project, #squeak-phone, a sketch of an alternative to Android for personal computing on a
mobile device.
These are one-person projects at present, and the current round of development is coming to a
close. This is a summary of where things stand.
Goals. Aim for a hackable, tweakable, pocket-sized Smalltalk system that’s also a phone.
Also, see what happens if we replace systemd, D-Bus etc with Syndicate-style
alternatives.
Outcomes. It runs! Smalltalk on a phone. Weird but fun alternative universe, not Android,
not systemd. You can make calls, send/receive SMS, use cellular data, WIFI, look at maps,
etc. No browser yet.
 Synit on PostmarketOS boot splash screen.
Synit on PostmarketOS boot splash screen.
Synit is my experimental alternative “system layer” for Linux. I chose to
use my #squeak-phone project as the initial vehicle for exploring the idea.
Squeak-phone uses the Syndicated Actor
Model in conjunction with Squeak
Smalltalk and a few other bits of software to have a foundation for
exploring an alternative universe of mobile personal computing.
Links
I’ve written a few posts about it both on this site and on
eighty-twenty.org). This page outlines the portion of the project that was funded by
NLNet’s NGI Zero. (Thanks, NLNet!) The Synit
project has a homepage at synit.org now, with links to
documentation and code.
Common Syndicate parts of the project of course remain here at
syndicate-lang.org and in the Syndicate git
repositories.
Booting Linux into a Syndicated world
The prototype Synit system is based on postmarketOS, which is an
Alpine Linux distribution for cellphones. Synit adds a few
custom Alpine packages, one of
which
does unspeakable things to the normal postmarketOS packages to outright replace /sbin/init
with a Syndicate replacement.
The first thing the Syndicated PID
1 does is
start a syndicate-server instance as the
root system bus, which then uses Erlang-style supervision patterns to spawn the rest of the
system.
Smalltalk as the phone UI
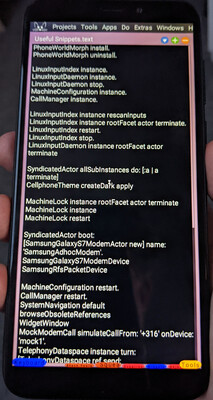 After booting, the most-recently-saved Smalltalk image comes back to life.
After booting, the most-recently-saved Smalltalk image comes back to life.
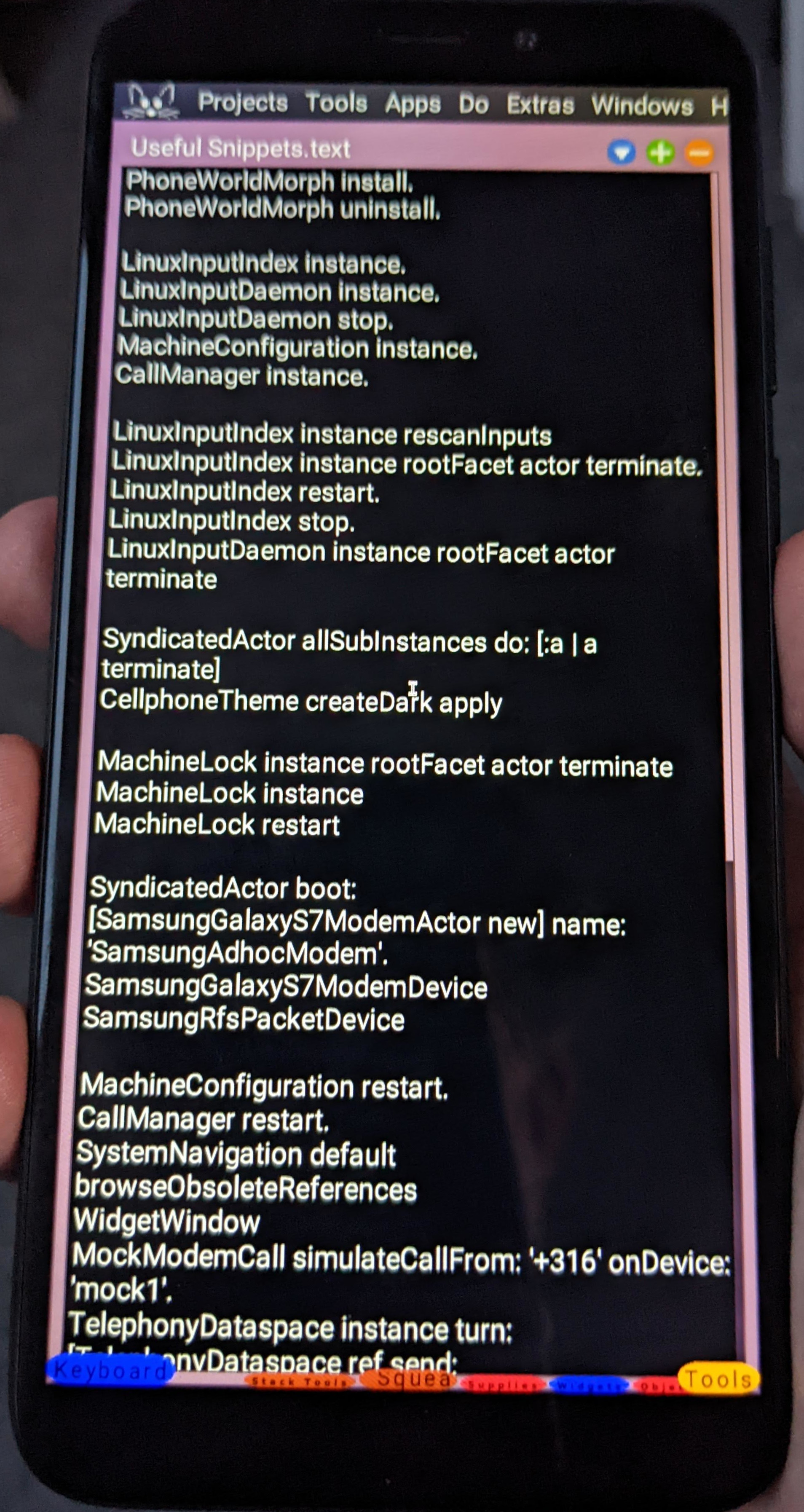
One of the actors started by the system bus is a Squeak Smalltalk image. The photo here shows
the Smalltalk image just after the phone completes booting: it has a Smalltalk workspace
visible, containing useful snippets of Smalltalk code for interacting with the phone that I can
execute with the tap of a (couple of) finger(s).
It’s a regular Smalltalk image, so I can make changes to the code, save snapshots, and so on.
When I reboot the phone, the most recent image snapshot is loaded.
Lots of languages working together
Both PID 1 and syndicate-server are written in Rust, but system actors can be written in any
language that speaks the Syndicate protocol; this
currently means TypeScript/JavaScript, Bash (!), Smalltalk, Python, Nim, Rust, and Racket.
Reactivity
The system is reactive. It self-organises around the information placed in the system
dataspace. Schemas are used to strongly
(dynamically) type the system.
Object-capabilities
are used to secure the system. Various system actors react to changes in the machine’s
environment, such as (dis)appearance of WIFI SSIDs, hotplugging of devices, and so on.
For example, placing a record
<configure-interface "lo" <static "127.0.0.1/8">> into the dataspace triggers an actor that
uses the ip command-line tool to set up the interface. Removing the record causes the same
actor to use ip again to tear the interface down. Likewise, addition of <configure-interface
"eth0" <dhcp>> causes startup of a DHCP client daemon; subsequent removal terminates the
daemon and removes the interface.
Squeak-phone Applications
One of the schemas,
ui.prs,
describes a Syndicate protocol for user interfaces. It’s a very rough sketch at the moment, and
woefully underdocumented - but here are a few “applications” written using it:
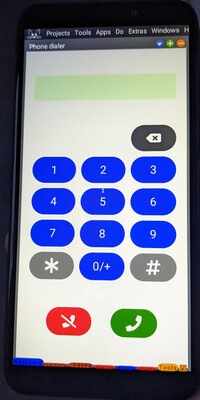 The dialer screen.
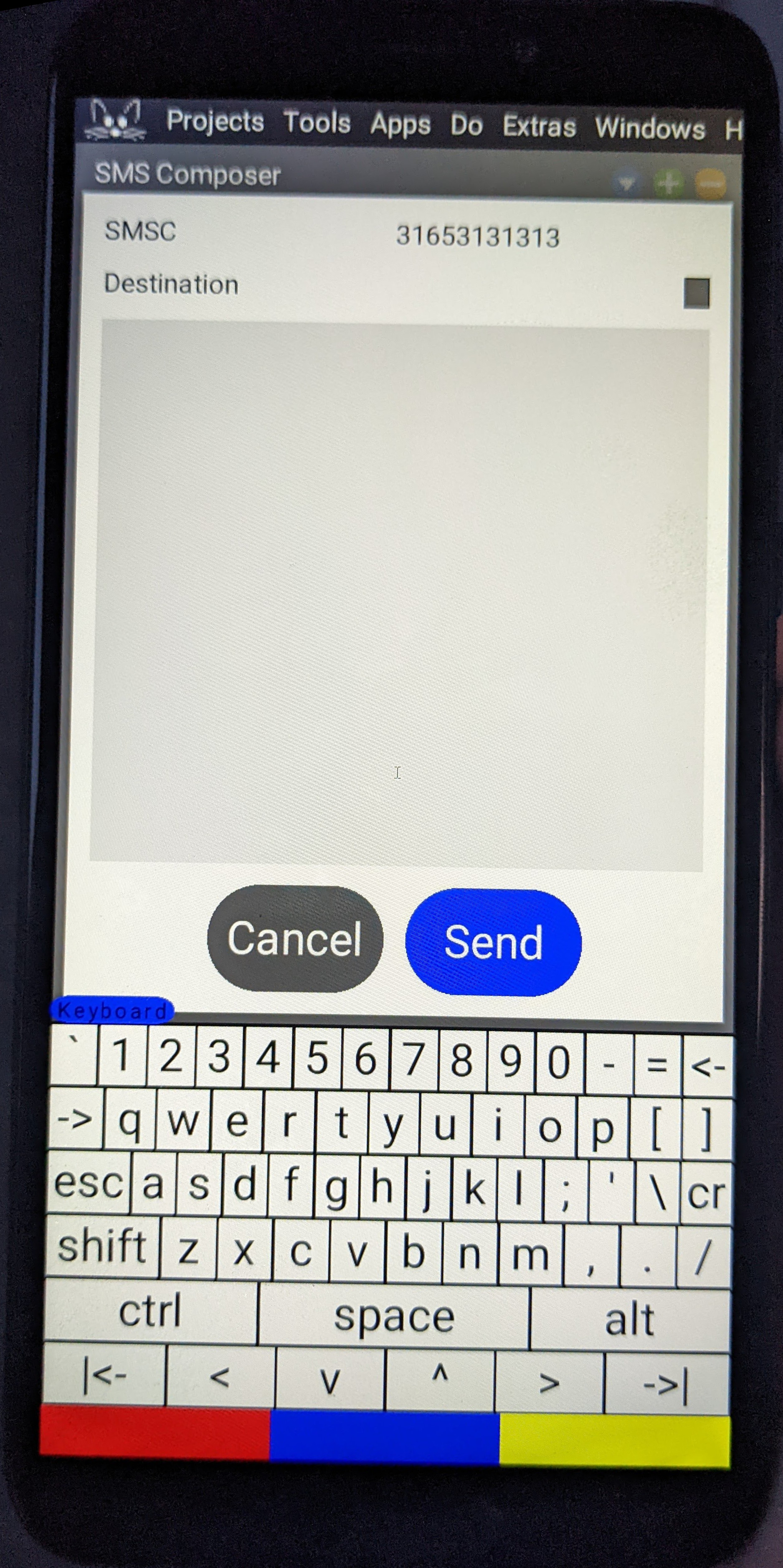
The dialer screen.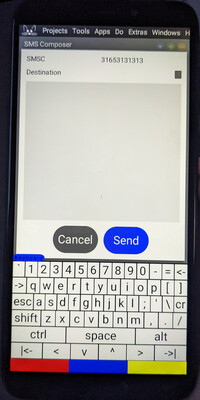 The SMS composition window.
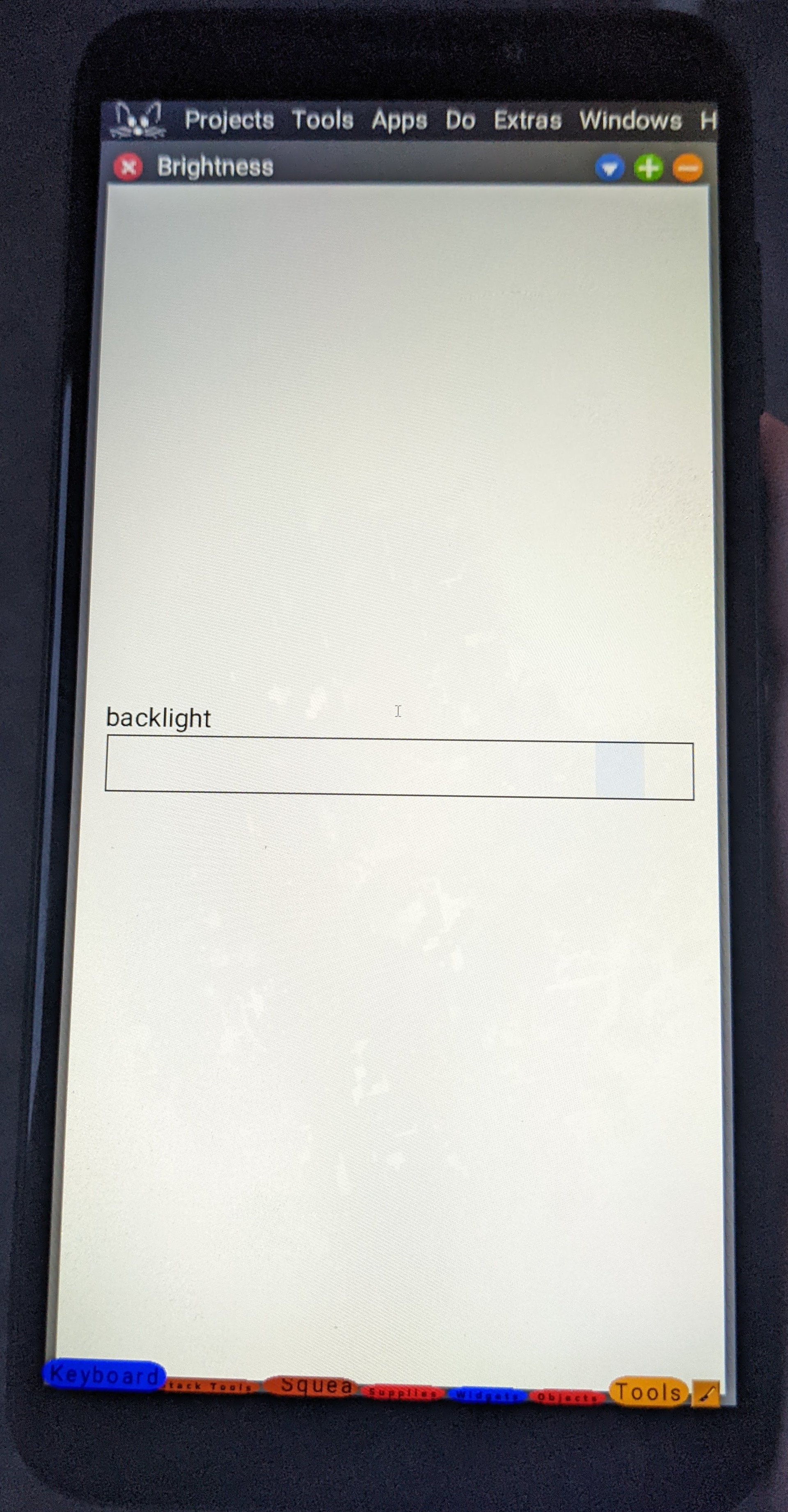
The SMS composition window.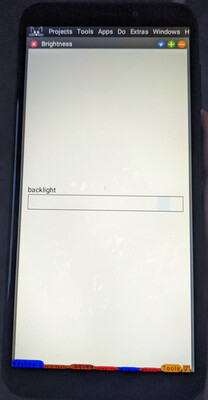 The brightness control.
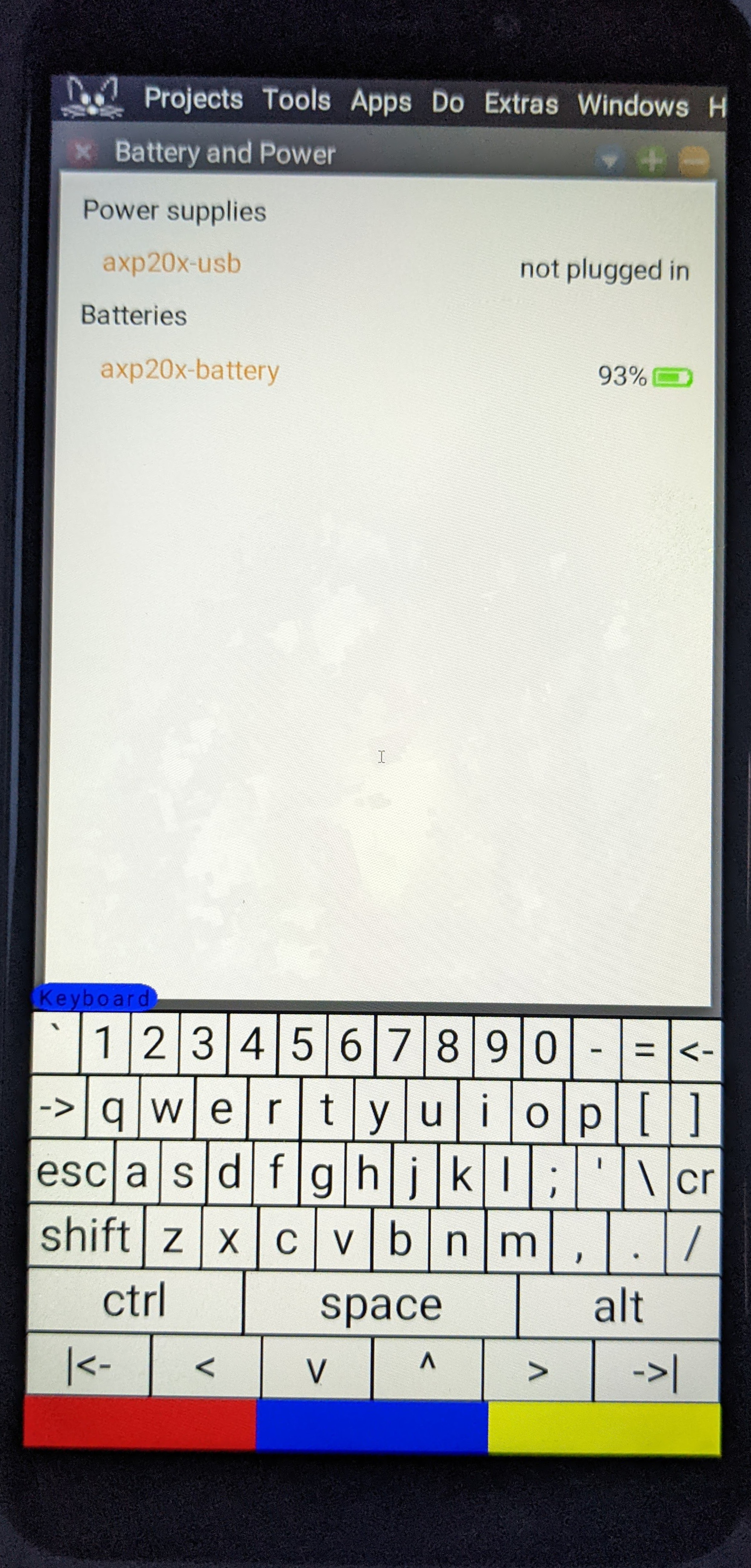
The brightness control.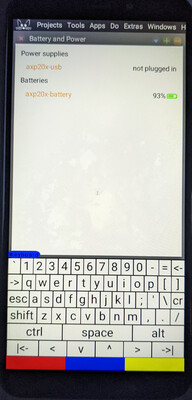 The battery and power display.
The battery and power display.
Each application is a Syndicate actor running either inside the Smalltalk image or as a
neighbouring process on the system, interacting with a Smalltalk UI daemon that speaks the
protocol defined in ui.prs.
The UI-presenting actors are separate from the actors that manage the underlying information,
such as the brightness status and control, or the details of the system’s current power status.
The on-screen keyboard is a simple Smalltalk
program. The red, blue, and
yellow rectangles beneath the keyboard are shift-like keys used to change the interpretation of
a finger tap: they correspond to left, middle, and right-clicks, respectively.
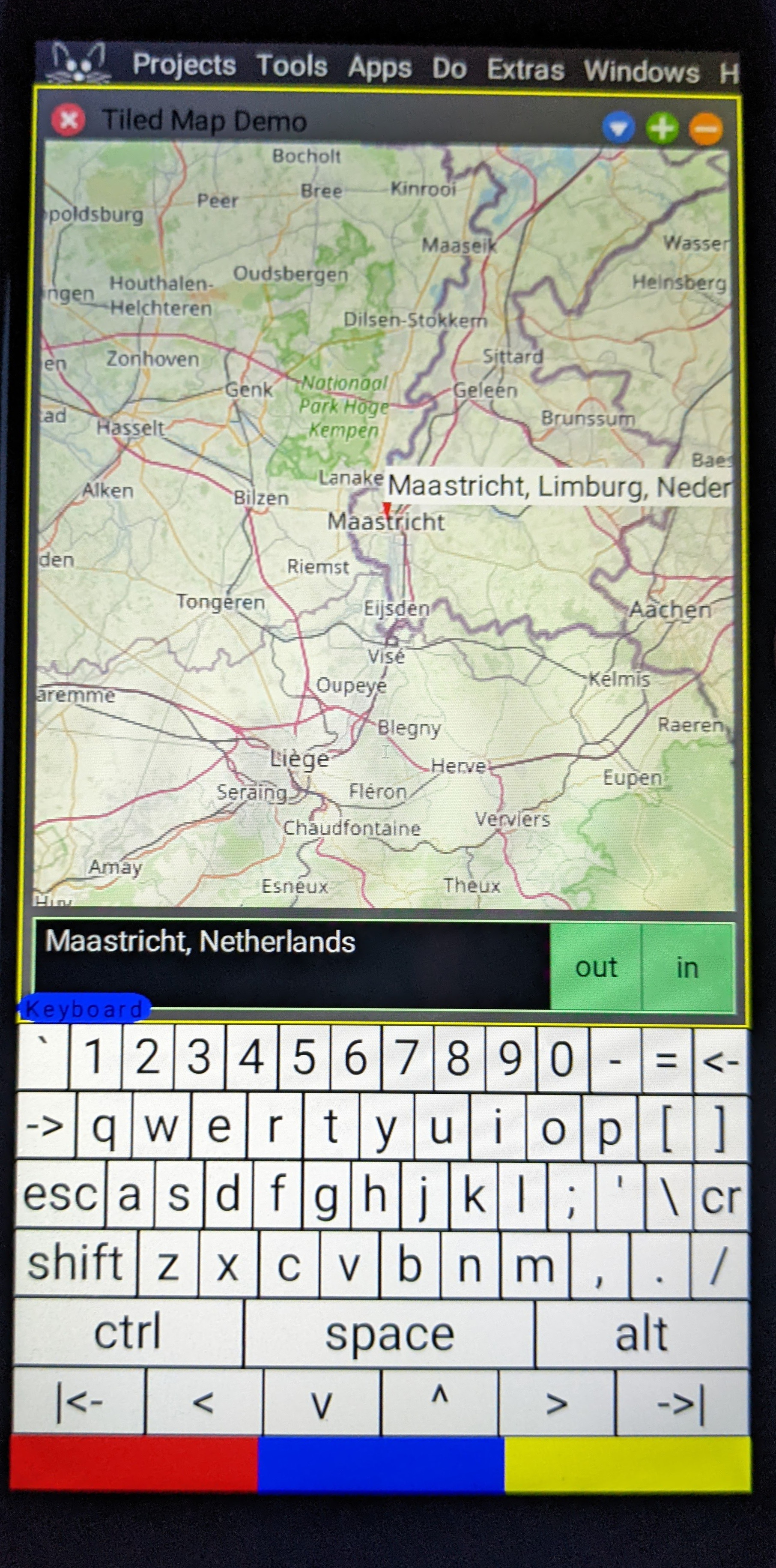
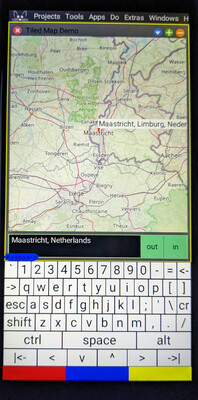 A tiled-map (“slippy map”) widget.
A tiled-map (“slippy map”) widget.
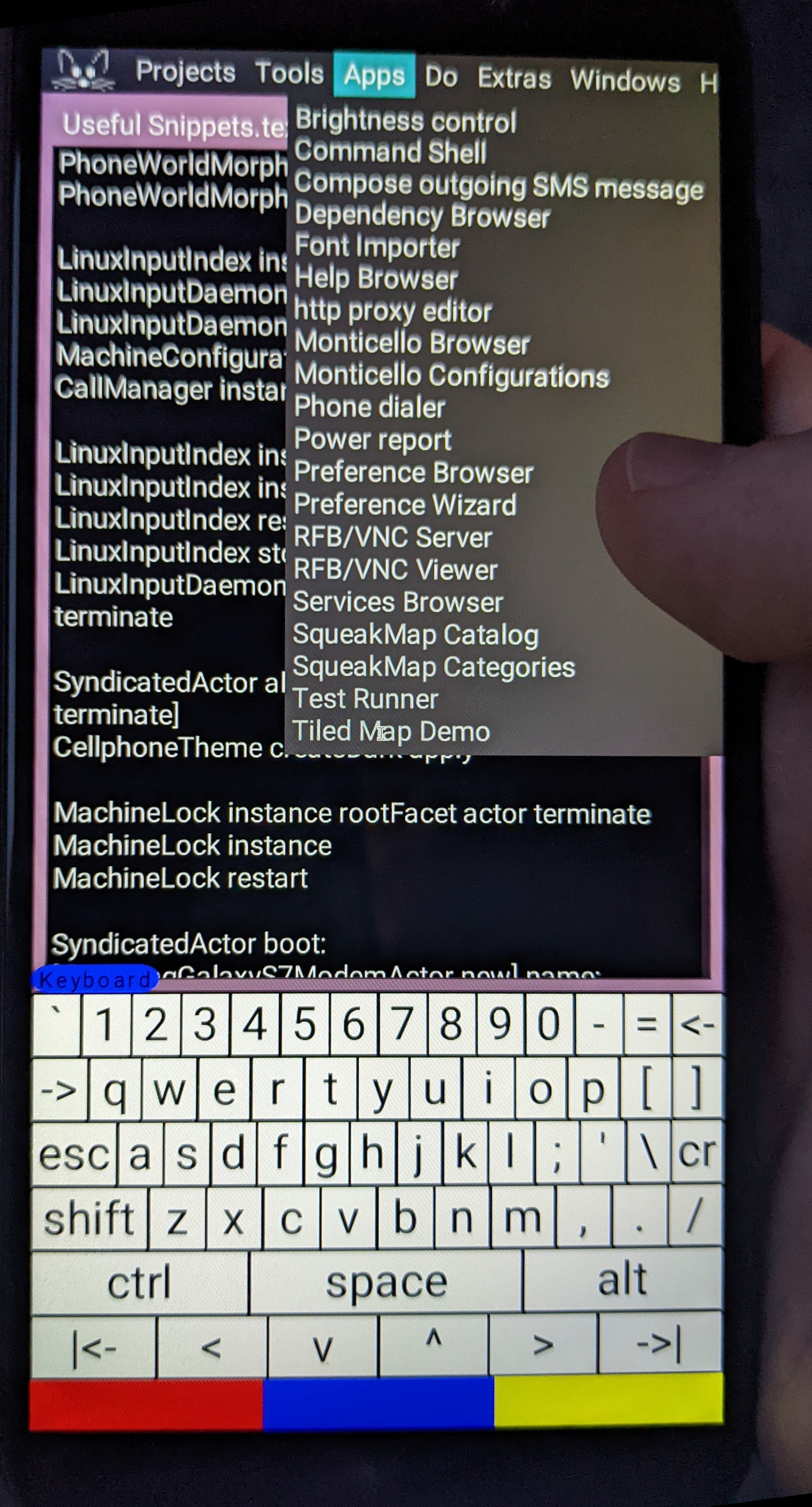
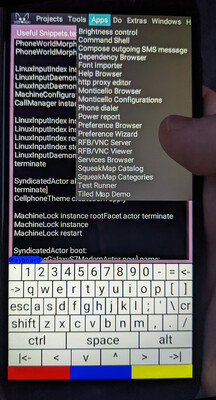 The placeholder “apps” menu, including both SqueakPhone and ordinary Squeak “applications”.
The placeholder “apps” menu, including both SqueakPhone and ordinary Squeak “applications”.
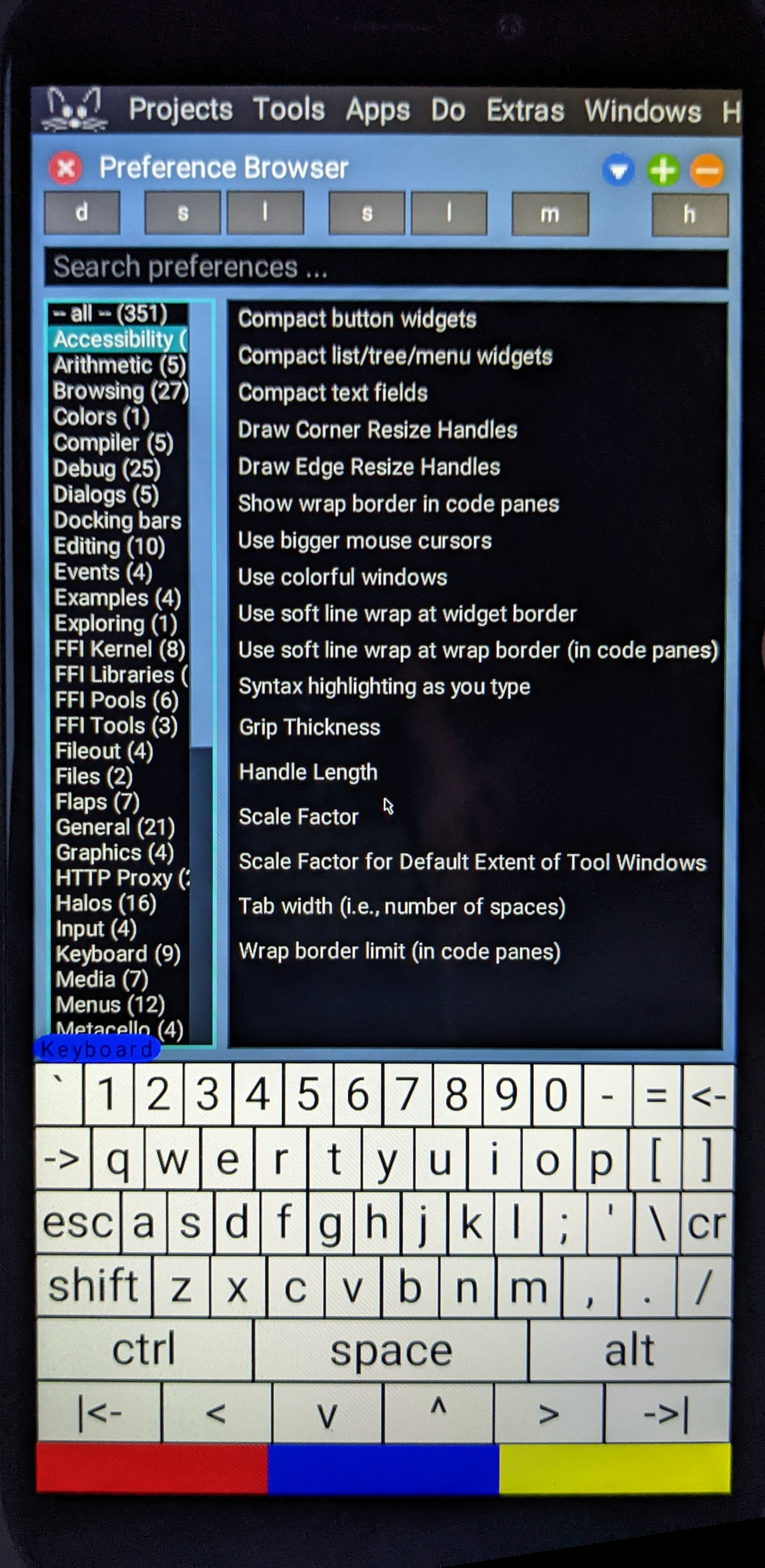
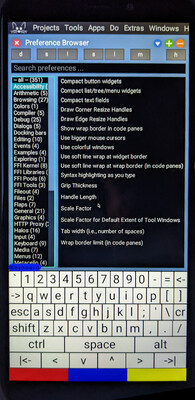 The ordinary Squeak preference browser.
The ordinary Squeak preference browser.
A little Smalltalk program wraps a
TiledMapMorph I wrote a few years ago
to provide a “map” application, backed by OpenStreetMap by
default.
The system enables cellular data by default, so the maps can be used when you’re out and about.
You can configure WIFI SSID/password information, too, but you have to do it using a text
editor at the moment. There’s only one of me!
Finally, it’s still very much a regular Smalltalk system, with only the lightest of
customisation for handheld use. All the normal Squeak “applications” are available, such as
version control, code editing, font management, preference settings etc.
Lessons learned
I think the experiment so far has been a success.
The big reusable pieces, likely to find application in other projects besides the continuation
of this one, are Preserves, Preserves
Schema, the Syndicated Actor
Model itself, and the
syndicate-server program.
The idea of synit—using Syndicate as a system layer, replacing D-Bus, systemd and so on—has
worked out really well, and I want to try it out for desktop and server systems, too.
Smalltalk-on-a-phone is also really promising, and it’s super fun to be able to hack about with
the phone without needing a separate desktop/laptop system to develop on. However, careful
design of both the user interfaces as well as the underlying system protocols will be crucial
to actually make a usable and securable system. The system-layer stuff is simple in comparison.
Lots remains to be done. I’m looking forward to it!